
For at least one exercise, we’re going to need to scrape data from a web site. (Depending on the direction you choose for your final project, you may need to do this again. In any case, it can be a handy thing to know how to do.) We’ll use Google’s Chrome web browser and the Scraper extension to get this done.
If you don’t already have the Chrome browser on your computer, please download and install it (Chrome is available for Windows, macOS, and Linux).
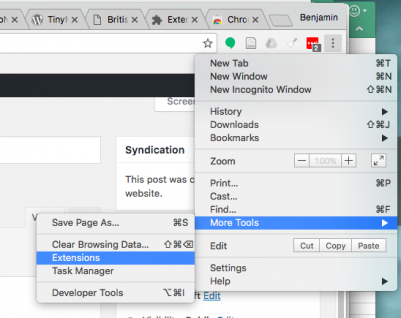
When you’ve installed Chrome, launch it. Click on the three vertical dots at the upper right of the window, then select More Tools > Extensions to go to the Chrome web store:
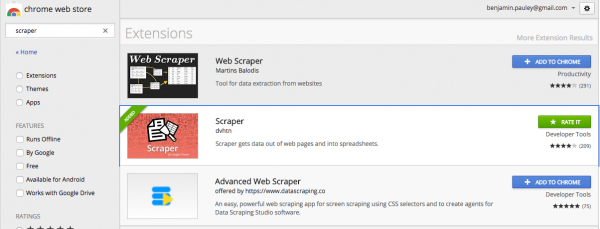
At the Chrome web store, search for “Scraper.” You’ll get a few different results, but you want the one developed by “dvhtn” (Dave Heaton). Click the blue “Add to Chrome” button to add this extension to your copy of Chrome. (I’ve already done so in this screenshot, so your screen will look different from mine):
We’ll end up having to learn a little bit of something called XPath to use the Scraper extension to extract data from web pages. We’ll work on this when we get to our unit on social networking, but you can find tutorials online (the Mozilla Developer Network has a good one, for instance). There appear to be a few different Chrome extensions that can help you figure out XPaths. One that seems pretty helpful is “xPath Finder” (which is said to be “offered by www.skyfz.com,” though no site seems to be active at that address…)